
读书时都学过二进制吧?核心就是 “逢二进一”,跟我们日常用的十进制(0-9,逢十进一)不一样。但计算机里特别讲究 “0”,它可不是 “没意义”,在内存里照样占一个 “位置”。
那问题来了:计算机里的 “位” 到底是什么?
常听人说 “32 位电脑”“64 位电脑”,这又啥意思?
估计不少人现在的表情是:
我完全懵了…
别急,往下看!

我们说点有趣的历史:
最早的计算机,可不是现在巴掌大的笔记本,那家伙得有三层楼那么高!

你没看错,就一台机器,不是一整个机房。
而且是真的叫 计~算~机~,只是用来计算数学。
它身上满是密密麻麻的插孔,每个插孔就是一个 “开关”,插上电线,就代表内存里的 “位” 是 1(打开);没插线,就是 0(关闭)。
所以说白了,计算机里的 “位”(英文 bit),本质就是个最基础的 “电子开关”:
- 1 位(1bit)= 内存最小单位;
- 每个位里只能存 0 或 1(要么关,要么开);
- 咱们之前说的所有字符、符号,转成二进制后,其实就是一串 “开 / 关” 的组合, 只不过现在的计算机把 “插线、拔线” 变成了电子信号,快到我们看不见而已。
至于 “32 位”“64 位”,简单理解就是:这台电脑一次能同时操控多少个 “开关”(位),32 位就是一次控 32 个开关,64 位就是一次控 64 个,操控得越多,处理数据的速度自然越快~

旁白:听了半天,终于是一脸懵逼的更懵逼了……
别急别急!现在已经明白位里的 0 代表关、1 代表开,咱们接着往下聊~
一个位(1bit)只能存 0 或 1,那八个位凑在一起,不管是 0000 0000、0101 1010,还是其他组合,都被称为 “字节”,记住核心关系:1 个字节(1B)=8 个位(8bit),8 个位 = 1 个字节。

光说数字 1(二进制 0000 0001)太简单,咱们拿 99 举例,看看它怎么变成二进制存进内存:
先列 8 位对应的 2 的幂次(从右到左依次是):128、64、32、16、8、4、2、1
| 7位 | 6位 | 5位 | 4位 | 3位 | 2位 | 1位 | 0位 |
| 2^7=128 | 2^6=64 | 2^5=32 | 2^4=16 | 2^3=8 | 2^2=4 | 2^1=2 | 2^0=1 |
| 2的7次幂 | 2的6次幂 | 2的5次幂 | 2的4次幂 | 2的3次幂 | 2的2次幂 | 2的1次幂 | 2的0次幂 |
我们说了,一个字节8位,都是从0位开始算,到第7位 总共8个位。以上就是一个字节里的数值。
目标是找≤99 的最大数:没有99的这个数值,就找到接近于99的64在第6位,现在的1个字节排列开关是:
0100 0000
这个位我们就像打开开关一样,把它打开。
但我们还没到99,那就 99-64=35;还有35。那我们就找靠近35的数值。
再找≤35 的最大数:32,在第5位。现在1个字节的排列开关是:
0110 0000
剩下 35-32=3;
接着找≤3 的最大数:2在第1位,现在1个字节排列开关是:
0110 0010
剩下 3-2=1;
最后找≤1 的最大数:1在第0位,刚好凑够 99;现在1个字节的排列开关是:
0110 0011
所以 99 的二进制就是 0110 0011,你们用手机或电脑搜 “二进制转十进制” 验证,结果肯定是 99~
这就是数字从键盘输入,到被编译器转成二进制存进内存,再从内存取出还原成数字的核心过程,现在应该有点懂了吧?

等等?有人质疑我说错了,2的8次幂是255,而不是128!!!

这位朋友问得好。我这里另外加一点知识,很乐意分享,因为我刚学的时候,也质疑了我的导师,导师也说我很强!!!
让我不用学了,因为我从不认真听课。
记住一个核心:8个位,就是2的8次幂等于255没错。但你更要懂一点,
每个位,都有一个独立的开关!!!
每个开关打开后,就会产生相加!!!
就比如:单独打开最高位,也就是上面的第 7 位,二进制是 10000000,对应的数值是 128;但如果你在打开第 0 位,也就是
10000001
得到的数值就是第7位和第0位数值相加,得到:129。
这次重要的来了:

1个字节里有8位,不管打开其中的几个开关,那几个开关对应的位的2次幂相加,就是他们显示的数值。如果8个位全打开,就是:
1111 1111
得到的数值就是从第0位的数值开始,加到第7位的所有数值,得出的结果数值是 1+2+4+8+16+32+64+128=255
其实还有一个符号位的,后面会说。
那电脑常说的 32 位、64 位又是什么意思?
这里先简单说(后面学指针会细讲):核心是 CPU 的 “地址总线宽度”,简单理解就是 CPU 能找到的内存范围 ,电脑内存是按字节寻址的,每个地址对应 1 个字节(8 位)。
先看 32 位电脑:
把 32 个 “开关” 全打开(32 个 1),对应的寻址总数是 2³² 个字节。
换算一下:2³² 字节 = 4294967296B,除以 1024 三次后,刚好是 4GB。
所以 32 位电脑的关键限制是,最多只能识别≈4GB 物理内存,就算插了更大的内存也用不上。
普通办公、小游戏够用,但运行大型绘图软件、开放世界单机游戏时,需要加载的模型、地图数据往往超过 4GB,可用内存不够就会卡顿、爆内存甚至蓝屏。
再看 64 位电脑:
它的地址总线能支持 2⁶⁴个字节寻址,理论上限约 16EB(1EB=1024PB),这辈子都用不完。
实际中受系统、主板限制,普通电脑最多支持 128GB 或 256GB 内存,完全能满足大型程序、多任务同时运行的需求。
不过要注意:想流畅处理大型数据,不光 CPU 得是 64 位,显卡、内存等配件也得跟上才行。

总结一下核心:
位(bit)是最小单位(0 = 关、1 = 开),8 位 = 1 字节;32 位电脑最多认 4GB 内存,适合日常用;64 位电脑支持大内存,能扛大型程序,本质就是 “开关数量” 决定了内存识别能力和数据处理上限~
算完了数字,再说说加减乘除符号、英文字母是怎么存进内存的
答案还是老样子:全部转为二进制!

我都说了,计算机只认 0 和 1,你们可别刚听完 32 位、64 位的寻址就忘了呀~ 是不是被刚才的内存上限计算搞懵啦?哈哈哈,那个先放一放,不用死记,只要记住前面数字怎么转二进制存进位里就行。现在重点说字符和字母:它们能转二进制,靠的是老外发明的 “翻译本标准”
也就是编码标准。
我们之前说了,编译器是一个工具,它需要一个标准,来执行工作。
我们在回顾一下:
“翻译本”(编码标准)和 “编译器”:
- 编译器咱们之前说过,是负责执行 “翻译动作” 的工具(把代码转成机器语言);
- 编码标准(翻译本):是编译器根据编码标准,标准了:字符、文字该对应什么二进制,不是随便定的。
咱们说的英文字母、加减乘除符号,用的 “翻译本” 叫 ASCII 码。
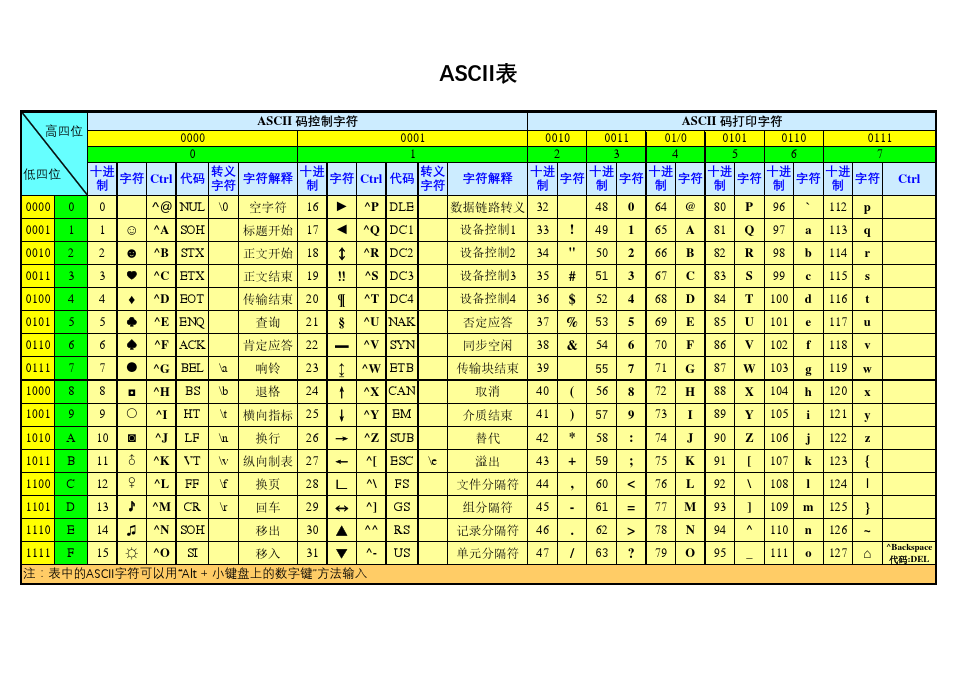
ASCII
这是国际制定的标准

它的规则很简单:每个字母(比如 'a'、'A')、符号(比如 '+'、'*')都对应一个唯一的十进制值(比如 'a' 对应 97,'+' 对应 43),再由这个十进制值转成二进制。而且这个规则是固定的,不用你写进代码里,编译器会自动按 ASCII 码翻译,再遵循stdio.h的标准存进内存。
接下来是文字,就说汉字怎么存进内存?
核心逻辑还是转二进制,但汉字数量多、结构复杂,ASCII 码总共才 128 个编码,根本装不下,所以得用另一本 “翻译本”。
有的人可能见过:办公软件、各类 APP 的右下角或设置里,常会出现 UTF-8,这就是 “万国翻译本”,全球通用。
它的逻辑是直接给每个汉字(或其他国家文字)定义唯一的二进制编码,你们外面看到有的转换是十六进制的,十六进制只是二进制的 “简写”(每 4 位二进制对应 1 位十六进制),更方便人类读写和存储,最终还是以二进制形式存入内存。不管是中文、英文、日文还是其他语言,UTF-8 都能覆盖。
当然,咱们也有自己的汉字 “翻译本”,GB2312 和 GBK。
GB2312 覆盖了常用简体汉字,GBK 则在它基础上扩展了繁体、生僻字,是专门针对汉字的编码标准,以前在国内软件里很常见,而且 GBK 兼容 GB2312(能识别 GB2312 的所有汉字)。
说到这,你们要是真理解了 “所有数据(数字、字符、文字)都靠编码标准转二进制存内存”,那编程的 50% 就已经吃透啦!是不是没想到这么简单?
而且别觉得 “编码标准、编程语言” 都是老外主导,国外的月亮没有那么圆了, 国外的技术壁垒正在被打破,咱们自己的工具和标准越来越强,甚至有的已经超越了。
比如华为推出的 仓颉编程,听说比 C 语言等传统语言更便捷,自带丰富的库函数标准,编译流程更简洁,不用像传统语言那样手动写大量引用指令。甚至能 “半逻辑打代码”,比自己瞎琢磨逻辑、写冗余代码效率高多了。
除此之外,国家相关部门也在研发自主操作系统,慢慢脱离对 Linux 核心的依赖。未来咱们有自己的编程工具、自己的系统标准,真的特别值得期待~